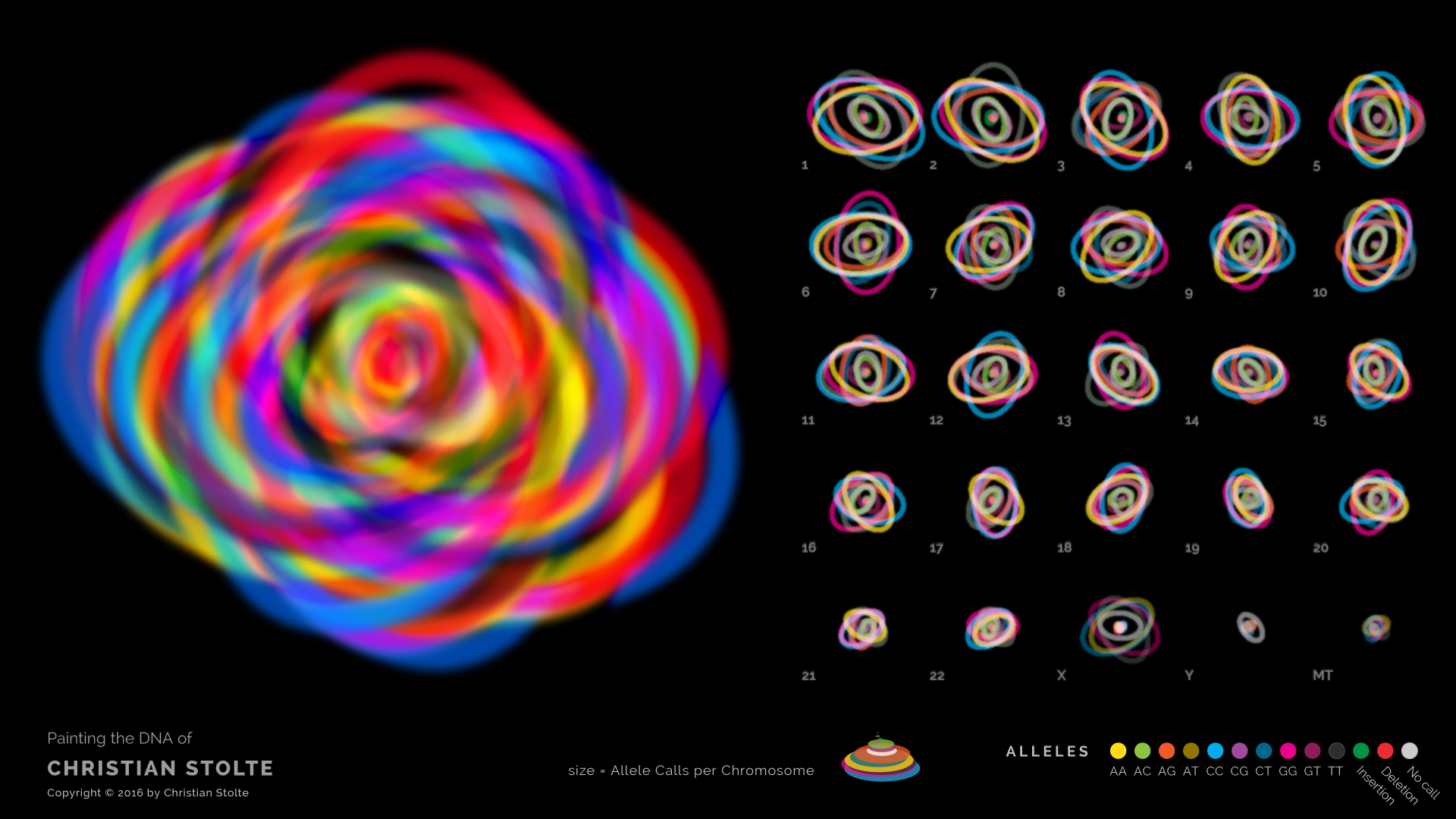
We use the visible differences between individuals to make quick judgements and group assignments. What we can’t see is what causes the differences – the genetic makeup of each person, and the differences between one genome and another.
For this project, I wanted find a concise form that makes genomic data visible and shows identifiable differences between genomic signatures, without getting hung up on details. In order to reduce the complexity and size of the datasets, I chose to explore if a coarse summary of genetic data, reducing a million points of difference down to thirteen aggregates per chromosome, would still preserve the individuality of each genome. As it turns out, the answer is yes.
The starting point are raw data files from the genetic service 23andMe, extracted from my own DNA and that of a couple of friends. Each file contains almost a million two-letter genomic position readouts. For each chromosome, counts of the observed letter combinations are translated to overlapping shapes of corresponding size, orientation, and color. The resulting artwork is different for each person.
For more details go to https://printmydna.com
(There you can also play with an interactive page to explore different designs ...)